Dezembro de 2021
Email: susumuasaka64@gmail.com
Os conflitos de merge são inevitáveis no desenvolvimento de software colaborativo e são disruptivos. Quando ocorrem, os desenvolvedores têm que parar seu trabalho atual, entender o conflito e o código circundante, e planejar uma resolução apropriada. No entanto, a maior parte dos conflitos não são problemáticos, alguns podem ser facilmente corrigidos, enquanto outros podem ser extremamente complicados para precisar da colaboração de várias pessoas. Neste artigo, pretendemos apresentar as técnicas que podem ser usadas para prevenir estes merges problemáticos. As técnicas serão analisadas no contexto de quatro workflows do Git diferentes: Git-flow, OneFlow, GitHub Flow e Desenvolvimento Baseado no Tronco.
O branching é considerado o feature matador do Git, permitindo que milhares de desenvolvedores trabalhem em paralelo sobre uma mesma base de código. No entanto, apesar do Git facilitar muito, o processo básico continua sendo o mesmo: cada desenvolvedor trabalha em uma cópia privada da base de código. Agora os desenvolvedores podem facilmente trabalhar em seus próprios features, mas surge um problema: como juntar as cópias novamente ao final do trabalho?
Os desafios com esse processo são os conflitos de merge. Estudo de Brindescu et al. (Brindescu et al. 2020) mostra que os conflitos de merge são prevalentes: cerca de 20% de todos os merges acabam em um conflito de merge.
Os conflitos de merge podem ser classificados em três tipos conforme a forma de sua detecção, por ordem crescente de dificuldade:
O conflito textual ocorre quando os desenvolvedores modificam os mesmos arquivos de código em paralelo. Este é o conflito que é detectado automaticamente pelo Git, mas requer intervenção humana para sua resolução;
O conflito semântico estático ocorre quando as falhas aparecem na análise do programa estática, no build ou IDE;
O conflito semântico dinâmico é o mais insidioso e dificultoso, ocorre quando as falhas aparecem somente em tempo execução. Esse conflito pode ser detectado por um teste que reproduza as condições da falha.
Os conflitos de merge têm impacto na qualidade do código, são perturbadores para o fluxo de trabalho de desenvolvimento. Para resolver um conflito de merge, um desenvolvedor tem que parar o que está fazendo e focar na resolução. Resolver um conflito requer que o desenvolvedor entenda as mudanças conflitantes, crie uma solução de consenso que satisfaça ambos os conjuntos de requisitos que impulsionaram as mudanças. Não há como criar um algoritmo para resolver conflitos automaticamente. Muitos times gastam uma quantidade excessiva de tempo lidando com seu emaranhado de branches.
Esses fatores podem levar os desenvolvedores a adiar a resolução do conflito ou “empurrar o problema com a barriga”, especialmente no caso do conflito semântico dinâmico. De fato, um estudo de Nelson et al. (Nelson et al. 2019) descobriu que 56.0% dos desenvolvedores adiaram pelo menos uma vez resolver um conflito de merge. No entanto, quanto mais tarde um conflito for resolvido, mais difícil é recordar a lógica das mudanças, o que torna o processo de resolução muito mais difícil (Fowler 2006). Como apropriadamente colocado por um participante do estudo de Nelson et al.:
Adiar um conflito de merge é simplesmente empurrar o problema com a barriga (para um precipício). Geralmente, a resolução do conflito só fica mais difícil com o passar do tempo
O estudo de Brindescu et al. (Brindescu et al. 2020) descobriu os principais fatores que influenciam a dificuldade dos conflitos de merge:
Neste artigo apresentamos quatro workflows que suportam o desenvolvimento em paralelo propiciado pelo Git, mas buscando minimizar a dificuldade dos conflitos de merge:
A ideia chave é o conceito de deslocamento à esquerda (Forsgren et al. 2016). Quando deslocamos para esquerda, menos coisas quebram na produção, porque quaisquer problemas são detectados e resolvidos mais cedo.
Pense no processo de entrega de software como uma linha de montagem de fabricação. A extremidade esquerda é o laptop do desenvolvedor onde o código se origina, e a extremidade direita é o ambiente de produção onde esse código será implantado. Quando deslocamos para esquerda, em vez de testar a qualidade apenas no final, temos vários loops de feedback ao longo do caminho para termos problemas menores de resolução mais fácil.
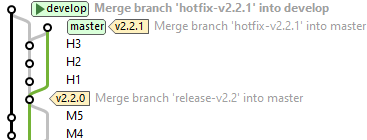
Git-flow tornou-se um dos workflows mais populares. Foi escrito por Vicent Driessen em 2010 (Driessen 2010), aparecendo quando o Git estava ficando popular. Nos dias anteriores ao Git, branching era frequentemente visto como um tópico avançado. Em comparação com o desajeitado Subversion, o Git tinha branching “leve”. Isto facilitou considerar vários branches como ativos (em paralelo) e fazer merge mais tarde. O mecanismo de merge do Git era muito bom e tinha rastreamento desde o início. Era mais eficaz do que outras tecnologias de merge anteriores para processar silenciosamente a complexidade.
Para ilustrar o Git-flow apresentamos na figura a seguir o diagrama de branches de um projeto exemplo. O diagrama de branches mostra os commits na ordem cronológica descendente.
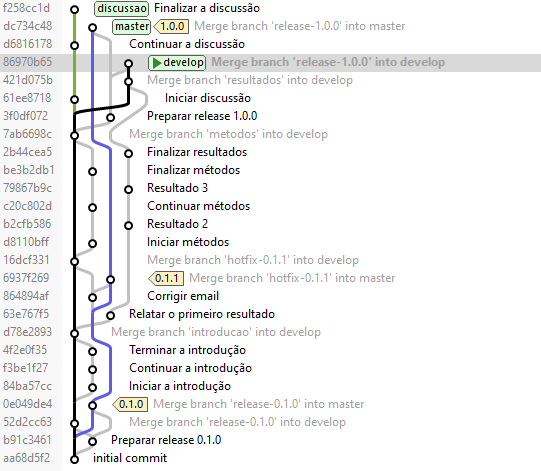
O branch principal ou tronco é um branch especial que reúne o trabalho entregue pelo time. Sempre que quisermos começar um novo trabalho, baixamos o branch principal para nosso repositório local para começar a trabalhar. Sempre que quisermos compartilhar nosso trabalho com o resto do time, atualizamos esse branch principal com o nosso trabalho, idealmente usando o processo de integração ao branch principal que discutiremos em breve.
Times diferentes usam nomes diferentes para o branch principal, muitas vezes encorajados pelas convenções dos sistemas de controle de versão usados. O Git-flow chama-o de “develop”. Os usuários do Git muitas vezes chamá-lo-ão de “master” ou “main”, usuários do Subversion geralmente chama-o de “trunk”.
Devemos salientar aqui que o branch principal é um branch único, compartilhado. Quando as pessoas falam sobre “develop” no Git-flow, podem querer dizer várias coisas diferentes, já que cada clone de repositório tem seu próprio “develop” local. Os times têm um repositório central: um repositório compartilhado que atua como o único ponto de registro e é a origem dos clones, geralmente chamado de “origin”. Começar um novo trabalho do zero significa clonar este repositório central. Se já temos um clone, começamos baixando o “origin/develop” para atualizá-lo. Nesse caso, o branch principal é o “origin/develop”.
O branch de produção é um branch cujo “head” sempre marca a última versão pronta para produção. De forma confusa, o Git-flow chama este branch de “master”, o que leva algumas pessoas a pensarem equivocadamente que este é o branch principal a que referimos na seção anterior.
Quando o código-fonte atinge um ponto estável e está pronto para ser liberado para produção, todas as mudanças são copiadas para o branch de produção e tagueadas com um número de versão. Consideramos isso como uma cópia em vez de um merge, pois queremos que o código de produção seja o mesmo que foi testado anteriormente.
Um processo automatizado pode implantar uma versão em produção sempre que um commit é feito no branch de produção.
Uma alternativa à utilização de branch de produção é aplicar um esquema de tagueamento do número de versão. Podemos então obter um histórico de versões observando os commits tagueados. A automação também pode ser baseada em atribuições de tags.
Além dos branches principais (principal e de produção), o Git-flow usa uma variedade de branches de apoio: para ajudar o desenvolvimento em paralelo entre os membros do time, facilitar o rastreamento de features, preparar releases em produção e ajudar a corrigir rapidamente problemas de produção em vôo. Ao contrário dos branches principais, estes branches têm sempre um tempo de vida limitado, visto que serão removidos após o uso.
Os diferentes branches que o Git-flow usa são os seguintes:
Cada um desses branches tem um propósito específico e está sujeito a regras estritas sobre quais branches podem ser sua branch de origem e quais branches que devem ser seu destino.
o branch principal.
o branch principal.
qualquer coisa exceto master, develop, release-* ou hotfix-*
Abrimos uma branch separada para cada feature quando começamos a trabalhar nele e continuamos trabalhando nesse branch.
Enquanto estamos trabalhando num branch de feature, outros commits estão pousando no branch principal. Então, devemos baixar regularmente as mudanças cometidas no branch principal para nossa branch de feature para detectar se há quaisquer conflitos. Isso deve ser feito obrigatoriamente antes da integração, de forma a garantir que não haverá conflitos na integração.
Note que este “merge ao contrário” não é a integração propriamente dita, visto que não subimos a feature de volta para o branch principal.
Quando terminarmos de trabalhar no feature, executaremos a integração ao branch principal: uma cópia do branch do feature ao principal, para incorporar o feature ao produto.
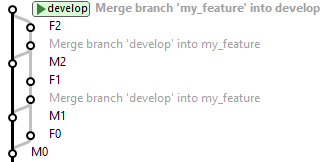
O Git-flow prescreve que seja usado o comando “merge” com a opção sem fast-forward, ao invés de “rebase”. A opção sem fast-forward faz com que o merge crie sempre um novo commit de merge, mesmo que o merge possa ser realizado com um fast-forward.
O Git-flow não diz nada sobre a duração dos branches de features, portanto, nem a frequência de integração esperada. Também não se sabe se o branch principal deve ser um branch saudável e, em caso afirmativo, que nível de saúde é necessário. A presença de branch de produção implica que o branch principal não é pronto para release.
O escopo do branch deve ser definido antes de sua criação e nunca realizar tarefas fora do escopo pré-definido. Caso seja necessário fazer outro trabalho, deve ser criado um branch separado para cada um.
o branch principal.
o branch principal e o branch de produção.
release-<número da versão de produção>
Um branch de release típico copia do branch principal, mas não permite que novos features sejam adicionados a ele. O time de desenvolvimento principal continua a adicionar tais features ao branch principal, e estes serão pegos em uma release futura. Os desenvolvedores que trabalham na release se concentram exclusivamente em remover quaisquer defeitos que impeçam a release de estar pronta para produção. Quaisquer correções a esses defeitos são criadas no branch de release e mergeadas ao branch principal. Assim que não houver mais falhas para lidar, o branch está pronto para a release em produção e será copiado ao branch de produção.
Embora o escopo de trabalho para correções no branch de release seja menor que de um branch de feature, fica cada vez mais difícil fazer o merge deles de volta ao branch principal com o passar do tempo. Branches inevitavelmente divergem, então a medida que mais commits modificam o branch principal, fica mais difícil fazer merge do branch de release para o branch principal.
Times que têm apenas uma versão em produção precisarão apenas de um único branch de release, mas alguns produtos terão muitas versões em uso em produção. Software que é rodado nas dependências do cliente só será atualizado quando esse cliente desejar. Muitos clientes relutam em atualizar, a menos que tenham novos features atraentes. Tais clientes, no entanto, ainda querem correções de bugs, especialmente se envolverem problemas de segurança. Nessa situação, o time de desenvolvimento mantém branches de release abertos para cada versão usada em produção e aplica correções a eles conforme necessário.
o branch de produção.
o branch de produção e o branch principal.
hotfix-<número da versão da correção>
Se um bug grave aparece em produção, então precisa ser corrigido o mais rapidamente possível. O trabalho neste bug terá uma prioridade maior do que qualquer outro trabalho que a equipe está fazendo, e nenhum outro trabalho poderá retardar a correção deste bug.
O trabalho de hotfix precisa ser feito com controle de versão, para que o time possa registrar e colaborar corretamente. Podem fazer isto abrindo um branch de hotfix no head do branch de produção e aplicando nele quaisquer alterações para o hotfix.
Quando terminar o trabalho, o hotfix deve ser copiado ao branch de produção para implantação. Então o hotfix deve ser aplicado ao branch principal para garantir que não haja uma regressão com a próxima release. Se o tempo entre as releases for longo, então o hotfix será feito em cima de código que foi alterado, assim será mais difícil fazer o merge. Neste caso, bons testes que expõem o bug são realmente úteis.
Recentemente em 2020, num adendo ao seu artigo original, Driessen (Driessen 2010) reconheceu que o Git-flow não é adequado para os times que fazem Integração Contínua (Continuous Integration) ou Entrega Contínua (Continuous Delivery):
Esta não é a classe de software que eu tinha em mente quando escrevi o post do blog 10 anos atrás. Se seu time está fazendo Entrega Contínua de software, eu sugeriria adotar um workflow muito mais simples (como o GitHub Flow) em vez de tentar encaixar o Git-flow no seu time.
Realmente, o Git-flow não foi feito para suportar a alta frequência de integração requerida pela Integração Contínua. Mais adiante discutiremos a Integração Contínua.
O Git-flow foi feito para a construção de software mais tradicional que é explicitamente versionado, ou precise suportar várias versões em produção, como software instalado nas dependências do cliente. De fato, ter várias versões em produção é um dos principais requisitos que demandam o uso de branches de releases.
Um branch de produção pode adicionar alguma conveniência ao workflow, mas muitas organizações consideram que o tagueamento funciona perfeitamente bem. O branch de produção é mais uma complicação desnecessária, que muitos equivocadamente usam como branch principal, até pelo nome adotado de “master”. Todos os outros workflows que discutimos neste artigo dispensa o uso do branch de produção.
Enquanto o Git-flow é muito popular, no sentido de que muitos dizem que o usam, é comum encontrar pessoas que dizem que estão usando Git-flow, mas estão fazendo algo bem diferente. Muitas vezes sua abordagem real está mais próxima do GitHub Flow.
Este workflow foi originalmente proposto por Adam Ruka em 2015 (Ruka 2015), em um artigo de crítica ao Git-flow.
Um dos aspectos definidores do OneFlow é o uso de um branch principal único (único perene), chamado aqui de “master”. Isso é conseguido via eliminação do branch de produção, sendo este substituído por um esquema de tagueamento.
Os branches de apoio (feature, release, hotfix) são temporários, e são usados principalmente como uma conveniência para compartilhar código com outros desenvolvedores e como uma medida de becape. Destarte, os features são integrados diretamente (via “rebase”) no branch principal, de forma a manter um histórico linear; já as releases e hotfixes são feitas de forma semelhante ao Git-flow. Na figura abaixo, mostramos como ficaria o diagrama de branch usando OneFlow no projeto exemplo, onde podemos verificar notável simplificação em relação ao Git-flow.
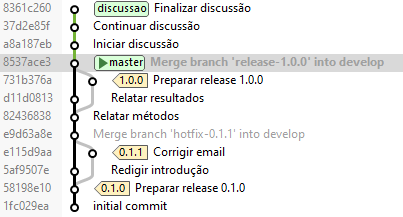
A vantagem mais óbvia, do ponto de vista do usuário do Git, é a facilidade de compreensão do histórico do Git, dada a linearidade obtida com a integração direta no branch principal; assim, a sequência dos commits é a narrativa de como o projeto foi feito. Você não publicaria o primeiro rascunho de um livro, então por que mostrar seu trabalho bagunçado? Quando está trabalhando em um projeto, pode precisar de um registro de todas suas tentativas e erros, mas, quando for a hora de mostrar seu trabalho para o mundo, pode querer contar uma narrativa direta de como sair de A para B. As pessoas neste campo usam comandos como “rebase” e “filter-branch” para rescrever seus commits antes de serem mergeados ao branch principal, de forma a contar a narrativa da maneira que for mais compreensível para futuros leitores. Estes comandos são considerados “avançados”, assim alguns times podem ter certa dificuldade em usá-los.
No contexto mais amplo deste artigo, a facilidade (e conveniência) estimulada pela integração direta ao branch principal favorecerá a abordagem aqui estimulada, de menor duração dos branches de apoio.
OneFlow se destina a ser um substituto imediato para Git-flow, o que quer dizer ser adequado em todas as situações em que o Git-flow é. De fato, é fácil migrar um projeto que esteja usando Git-flow para OneFlow.
Como foi proposta no artigo original, da mesma forma que o Git-flow, o Oneflow não pode ser usado em projetos em que tenham mais do que uma versão em produção. Mas essa deficiência pode ser sanada mantendo vários branches de release ativos, um para cada versão em produção, como mostramos na seção sobre o Git-flow.
Da mesma forma que o Git-flow, o Oneflow é inadequado para projetos que usam Integração Contínua (ou Entrega Contínua). O OneFlow também não foi feito para suportar a alta frequência de integração requerida pela Integração Contínua. Mais adiante discutiremos a Integração Contínua.
Apesar do sucesso do Git-flow, a complexidade desnecessária de sua estrutura de branching para aplicações web incentivou muitas alternativas. Com o aumento da popularidade do GitHub, não é surpresa que uma abordagem leve de branching usada por seus desenvolvedores se tornasse uma abordagem bem conhecida: o GitHub Flow. A melhor descrição foi feita por Scott Chacon em 2011 (Chacon 2011).
O GitHub Flow foi conscientemente baseado em, e uma reação contra, o Git-flow. A diferença essencial entre os dois é um tipo diferente de produto, o que significa um contexto diferente, portanto, abordagens diferentes. O Git-flow assumiu um produto com várias versões em produção. O GitHub Flow assume uma única versão em produção com alta frequência de integração em um branch principal pronto para a release. Com esse contexto, o branch de release não é necessário. Os problemas de produção são corrigidos da mesma forma que os features regulares, então não há necessidade de branch de hotfix, no sentido de que um branch de hotfix geralmente representa um desvio do processo normal. Remover esses branches simplifica drasticamente a estrutura de branching para a branch principal e branches de feature.
O GitHub Flow chama sua branch principal de “master”. Os desenvolvedores trabalham em branches de feature. Chacon indica que os branches de feature podem ser uma única linha de código até durar duas semanas. O processo pretende funcionar da mesma forma nessa faixa. O mecanismo de Pull Request faz parte da integração com o branch principal e é usado para a revisão pré-integração.
No GitHub Flow deve-se assegurar que todo código, integrado ou não, seja mantido no repositório central. Nesse caso, o desenvolvedor deve cometer no seu branch de feature localmente e subir regularmente seu trabalho para o branch com o mesmo nome no servidor. Isso permite que outros membros do time possam ver no que está trabalhando, mesmo que ainda não esteja integrado ao trabalho de outras pessoas.
Chacon em seu artigo explica que um dos aspectos visados na criação do GitHub Flow é que o GitHub pratica a Entrega Contínua: as entregas para produção acontecem diariamente ou mesmo várias vezes ao dia.
A frequência com que fazemos integração tem um efeito extremamente poderoso sobre a forma como um time trabalha. Estudos do Relatório State of DevOps (Forsgren et al. 2016) indicaram que os times de desenvolvimento de elite integram mais frequentemente do que os de baixo desempenho.
A integração frequente aumenta a frequência de merges, mas reduz sua complexidade e risco. O problema com grandes merges não é tanto o trabalho envolvido com eles, é a incerteza desse trabalho. Em cerca de 80% das vezes, até mesmo grandes merges não dão problemas, mas ocasionalmente dão enormes problemas. Essa dor ocasional acaba sendo pior que uma dor regular.
A integração frequente também alerta os times para conflitos com muito mais antecedência. Esta vantagem está conectada com a vantagem anterior, é claro. Merges difíceis são geralmente o resultado de um conflito latente no trabalho do time, surgindo apenas quando a integração (e testagem) acontece.
O que muita gente não percebe é que um sistema de controle de versão, como o Git, é uma ferramenta de comunicação. Permite que um desenvolvedor veja o que outras pessoas do time estão fazendo. Com integrações frequentes, não é apenas alertado rapidamente quando há conflitos, mas também fica mais ciente do que todos estão fazendo, e como a base de código está evoluindo. Somos menos indivíduos hackeando independentemente e mais um time trabalhando em conjunto.
Para termos um branch pronto para release é essencial manter o branch principal saudável. Assim o head do branch principal pode sempre ser colocado diretamente em produção.
Para conseguirmos esse feito, de manter a branch principal sempre saudável, é fundamental que o time trabalhe com código de autoteste. Esta prática de desenvolvimento quer dizer que, à medida que escrevemos o código de produção, também escrevemos um conjunto abrangente de testes automatizados para podermos ter confiança de que, se esses testes passarem, o código não conterá bugs.
Há uma tensão em torno do grau de testagem para fornecer confiança suficiente da saúde. Muitos testes mais completos requerem tempo demais para serem executados. Os times lidam com isso separando testes em vários estágios em um pipeline de implantação. O primeiro estágio desses testes deve ser executado rapidamente em menos de dez minutos, mas ainda ser razoavelmente abrangente. Referimos a tal suíte como a suíte de commit, embora seja frequentemente referida como “os testes unitários”, porque a suíte de commit é normalmente a união dos testes unitários.
Teste de software é um problema combinatório. Por exemplo, cada elemento de condição requer pelo menos dois testes: um com um resultado “verdadeiro” e um com um resultado “falso”. Como resultado, quase sempre o código de teste acaba ficando maior do que o código de produção.
O código rodar sem bugs não é o suficiente para dizer que o código seja bom. De modo a manter um ritmo constante de entrega, precisamos manter também a qualidade interna do código alta. As técnicas usadas para assegurar isso são: análise de programa estática (feita no build ou pelo IDE) e revisão pré-integração (feita pelo time).
A eficácia do branch principal pronto para release é governada pela frequência de integração do time. Se o time normalmente integra uma nova feature apenas uma vez por mês, então provavelmente estará em lugar ruim e uma insistência em um branch principal pronto para release pode ser uma barreira para sua melhoria. O lugar ruim é que não podem responder tempestivamente às necessidades de mudanças do produto, porque o tempo de ciclo da ideia à produção é muito longo. Também são mais suscetíveis de ter merges complexos porque cada feature é grande.
A chave para sair dessa armadilha é aumentar a frequência de integração, mas, em muitos casos, isso pode ser difícil de conseguir mantendo um branch principal pronto para release. Nesse caso, muitas vezes é melhor desistir do branch principal pronto para release, incentivar uma integração mais frequente e usar branch de release para estabilizar o branch principal para a produção.
No contexto da integração em alta frequência, um branch principal pronto para release tem a vantagem óbvia da simplicidade. Não há necessidade de se preocupar com todas as complexidades dos vários branches do Git-flow. Mesmo hotfixes podem ser tratados como se fossem features regulares.
Além disso, manter o branch principal pronto para release incentiva uma disciplina valiosa. Mantém a prontidão para produção no topo das mentes dos desenvolvedores, garantindo que problemas não entrem gradualmente no sistema, seja como bugs ou como problemas de processo que retardam o ciclo do produto. A disciplina completa de Entrega Contínua, com desenvolvedores integrando muitas vezes ao dia no branch principal sem quebrá-la, parece assustadoramente difícil para muitos. No entanto, uma vez alcançada e se tornando um hábito, os times descobrem que isso reduz notavelmente o estresse e é relativamente fácil de continuar. É por isso que é um elemento-chave da fluência de entrega do modelo Agile Fluency (Shore and Larsen 2018).
O modelo de Pull Request (PR) introduzido pelo GitHub é o modelo dominante de revisão pré-integração hoje. O conceito estava disponível a partir do lançamento do GitHub em 2008 e revolucionou o desenvolvimento de software de código aberto e empresarial. Google estava secretamente fazendo a mesma coisa desde 2005, e a apresentação de Guido van Rossum (Kennedy 2006) do Mondrian em 2006 vazou isso para o mundo.
Chacon em seu artigo cita que o Pull Request é utilizada mais como uma visão de conversação do branch do que como uma solicitação de integração propriamente dita. Podem enviar um Pull Request para dizer “Preciso de ajuda ou revisão sobre isto” além de “Por favor, fazer merge disto”.
No GitHub Flow todo o código deve ser revisado em Pull Request antes de ser integrado. Para serem eficazes, essas revisões não podem ser muito rápidas. Porém, muitos times que usam revisões pré-integração não as fazem rapidamente o suficiente. O valioso feedback que podem fornecer, então, chega tarde demais para ser útil. Uma regra prática para as revisões é que ela deve ser começar rapidamente, no máximo duas horas depois do Pull Request, e durar cerca de metade do tempo de desenvolvimento da feature.
O branch de feature de curta duração pode ter recebido muitos commits antes do desenvolvedor iniciar o Pull Request. Alguns times fazem squash e rebase das mudanças em um commit único ligado diretamente ao branch principal, de forma a manter o histórico linear, à moda do OneFlow, antes de iniciar a revisão pré-integração.
Paul Hammant (Hammant 2017b) escreveu um site detalhado para explicar essa abordagem.
O Desenvolvimento Baseado no Tronco se concentra em fazer todo trabalho no branch principal (chamado de “tronco”), usando branches de curta duração (menor que dois dias).
Times menores cometem diretamente no branch principal, da mesma forma que o OneFlow.
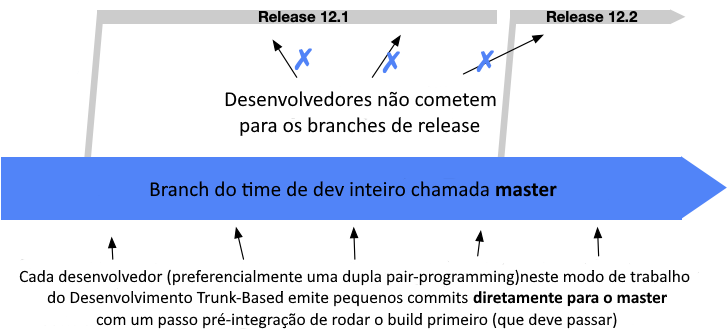
Times maiores podem usar branches de features de curta duração.
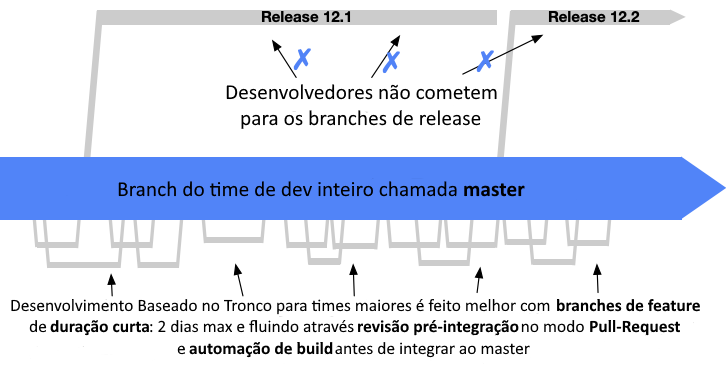
Os times podem usar branch de release (chamado de “branch para release”) ou branch principal pronto para release (chamado de “release a partir do tronco”).
Google (Potvin and Levenberg 2016) faz Desenvolvimento Baseado no Tronco e tem mais de 35 mil desenvolvedores nesse tronco monorepo único com mais de 2 bilhões de linhas de código.
Se um time estiver fazendo implantações em produção mensalmente, então também terão que subir versões de correções de bugs entre as releases planejadas. Para facilitar isso, é comum que os times de Desenvolvimento Baseado no Tronco façam um branch de lançamento “just in time”: digamos alguns dias antes da release. Isso se torna um local estável, dado que os desenvolvedores estão mandando seus commits para o branch principal em velocidade máxima.
Os desenvolvedores continuam cometendo na maior frequência para o branch principal e não desaceleram ou congelam com a proximidade de uma release. Os desenvolvedores como um grupo não cometem no branch de release.
Um problema com a aplicação dos commits de correção no branch de release, como é feito no Git-flow, é que é muito fácil deixar de fazer merge deles para o branch principal, principalmente porque fica mais difícil devido à divergência. A regressão resultante é muito embaraçosa.
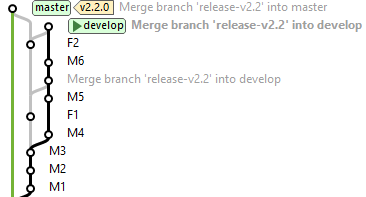
A melhor prática para os times de Desenvolvimento Baseado no Tronco é criar os commits de correção no branch principal, e apenas, quando estiverem funcionando lá, fazer o “cherry-pick” para o branch de release.
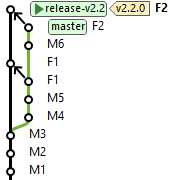
Um cherry-pick é quando é feito merge de um commit de um branch para outro, mas os branches não são mergeados. Ou seja, apenas um commit é mergeado, não os commits anteriores desde o ponto de ramificação. No exemplo da figura, se fizéssemos o merge regular de F1 ao branch de release, isso incluiria M4 e M5. O cherry-pick pode ser conflituoso, pois pode depender de mudanças feitas em M4 e M5.
A desvantagem de escrever correções de releases no branch principal é que muitos times acham mais difícil fazê-lo, e é frustrante corrigi-lo de uma maneira no branch principal e ter que retrabalhar no branch de release antes que a release possa ocorrer. Isto é particularmente verdadeiro quando há pressão para a release sair logo.
O processo de fazer merge de commits do branch principal para o branch de release usando “cherry-pick” é um papel para um único desenvolvedor do time. Mesmo assim, é uma atividade de tempo parcial. Talvez deva ter um rodízio de desenvolvedores para exercer o papel a cada dia.
Visto que um time tenha experimentado que a integração em alta frequência é mais eficiente e menos estressante, uma pergunta natural é “até que frequência podemos chegar?”. Branching por feature implica um limite inferior ao tamanho do branch: não pode ser menor que um feature coesivo.
A Integração Contínua (CI) aplica um gatilho diferente para a integração: integra sempre que fizer um pedaço do feature e seu branch ainda estiver saudável. Não há nenhuma expectativa de que o feature esteja completo, como no Git-flow, apenas que tenha havido uma quantidade de mudanças de valor na base de código. A regra de ouro é “todo mundo comete ao branch principal pelo menos uma vez por dia”. Na prática, a maioria dos praticantes faz a integração muitas vezes por dia.
Quando se faz Pull Request para revisão pré-integração, se admite branches de features com duração máxima de dois dias: um dia para o desenvolvimento isolado mais um dia para o Pull Request.
Os desenvolvedores que usam a CI precisam se acostumar com a ideia de se atingir pontos de integração com um feature parcialmente construído. Precisam considerar como fazer isso sem expor um feature parcialmente construído no sistema em execução.
Branch por abstração é uma técnica (Hammant 2017a) para fazer uma mudança em grande escala gradualmente, que permite fazer releases da aplicação regularmente enquanto a mudança ainda está em andamento.
Se não houver maneira de ocultar facilmente o feature parcial, podemos usar Flags de Feature. Além de esconder um feature parcialmente construído, tais flags também permitem que o feature seja revelado seletivamente a um subconjunto de usuários: muitas vezes útil para uma release gradual de um novo feature.
A integração de features parcialmente construídos preocupa particularmente aqueles que se preocupam em manter o branch principal saudável. Consequentemente, aqueles que usam a CI também precisam de Código de Autoteste para haver confiança de que ter features parcialmente construídos no branch principal não aumenta a ocorrência de bugs. Com esta abordagem, os desenvolvedores escrevem testes para os features parcialmente construídos conforme estão escrevendo esse código do feature, submetendo juntos tanto o código do feature quanto os testes no branch principal.
Uma pesquisa feita por Luke e Prince (Luke and Prince 2017) descobriu que a maioria dos participantes não conseguia definir de forma completa a CI. No entanto, muitos que deram uma definição incompleta, faltando especificamente a necessidade de se integrar ao branch principal diariamente, disseram estarem praticando a CI. Com exceção de pouco mais de 10%, todos que usavam uma ferramenta de CI/CD disseram estarem praticando CI. Parece que o uso de uma ferramenta de CI/CD é bastante sinônimo de fazer CI. Um nome melhor para essas ferramentas seria ferramentas de build contínuo.
Dos workflows discutidos neste artigo, somente o GitHub Flow e o Desenvolvimento Baseado no Tronco suportam a alta frequência de integração exigida pela CI.
Martin Fowler (Fowler 2020) fez uma comparação muito interessante entre o Branching por Feature completo e a Integração Contínua.
O Branching por Feature completo, como usado no Git-flow, parece ser a estratégia de branching mais comum na indústria no momento, mas há um grupo vocal de praticantes que argumentam que a Integração Contínua é geralmente uma abordagem superior. A principal vantagem que a Integração Contínua fornece é que suporta maior frequência de integração, muitas vezes muito maior.
Como já indicamos, a maior frequência de integração leva a uma integração menos complicada e menos medo de integração. Isso é muitas vezes uma coisa difícil de se comunicar. Em um mundo de integração a cada poucas semanas ou meses, a integração provavelmente será uma atividade muito preocupante. Pode ser difícil acreditar ser algo que possa ser feita muitas vezes por dia. Mas a integração é uma daquelas coisas em que a frequência reduz a dificuldade. É uma noção aparentemente masoquista: “se dói, faça-o com mais frequência”. Mas, quanto menores as integrações, menos provável é que se transforme num merge monstruoso de miséria e desespero. Com branching por features, isso requer features menores: de dias, não de semanas.
A Integração Contínua permite que um time obtenha os benefícios da integração em alta frequência, enquanto desacopla o comprimento do feature da frequência de integração. Se um time prefere features de uma ou duas semanas, a Integração Contínua permite que faça isso, obtendo assim todos os benefícios da maior frequência de integração. Os merges são menores, exigindo menos trabalho para resolver os conflitos. Mais importante ainda, como explicamos na seção sobre GitHub Flow, fazer merges com mais frequência reduz o risco de um merge problemático, tanto elimina as surpresas ruins que isso traz, como reduz o medo geral de fazer merge. Se surgirem conflitos no código, a integração em alta frequência os descobrirá rapidamente, antes mesmo que levem a esses problemas de integrações dificultosas.
A desvantagem clara da Integração Contínua é que falta o senso de fechamento dessa integração climática com o branch principal. Não é só uma comemoração perdida, é um risco se o time não for bom o bastante para manter um branch saudável. Manter todos os commits de um feature juntos torna possível decidir mais tarde sobre a inclusão de um feature em uma próxima versão. Os times que querem fazer Integração Contínua devem desenvolver um regime de testes forte para poderem ter certeza de que o branch principal permanece saudável, mesmo com muitas integrações por dia. Alguns times acham essa habilidade difícil de imaginar, mas outras acham possível e libertadora. Esse pré-requisito quer dizer que o branching por feature é melhor para times que não forçam um branch saudável e requerem branches de release para estabilizar o código antes da release.
Enquanto o tamanho e a incerteza dos merges são os problemas mais óbvios com o branching por feature, o maior problema com isto pode ser dele deter a refatoração. A refatoração é mais eficaz quando é feita regularmente e com pouco atrito. A refatoração reduzirá conflitos, se esses conflitos não forem detectados e resolvidos rapidamente, o merge fica preocupante. A refatoração funciona melhor com uma alta frequência de integração, então não é surpresa que se tornou popular como parte da Extreme Programming (Beck 2000), que também tem a Integração Contínua como uma de suas práticas originais. O branching por feature também desencoraja os desenvolvedores de fazer mudanças que não são vistas como parte do feature que está sendo construído, o que prejudica a capacidade de refatoração para melhorar de forma constante uma base de código.
Quando nos deparamos com estudos científicos de práticas de DevOps, geralmente não ficamos convencidos devido a sérios problemas com sua metodologia. Uma exceção é o State of DevOps Report (Forsgren et al. 2016), que desenvolveu uma métrica de desempenho de entrega de software, que se correlacionou a uma medida mais ampla de desempenho organizacional, que se correlaciona com métricas de negócio como retorno do investimento e rentabilidade. Em 2016, avaliaram pela primeira vez o Desenvolvimento Baseado no Tronco e descobriram que contribui para um maior desempenho de desenvolvimento de software:
A ideia que os desenvolvedores devem trabalhar em pequenos lotes a partir do mestre ou tronco, em vez de em branches de features de longa duração é ainda uma das ideias mais controversas do cânone ágil, apesar do fato que é a norma em organizações de alto desempenho, como o Google (Potvin and Levenberg 2016).
Descobrimos que ter branches com duração muito curtas (menos que um dia) antes de serem mergeados ao tronco e menos de três branches ativos no total, são aspectos importantes da Entrega Contínua, e todos contribuem para um desempenho mais elevado. Assim como fazer merge ao tronco ou mestre diariamente.
Neste artigo, investigamos diferentes aspectos que podem impactar o nível de dificuldade em resolver conflitos de merge. Avaliamos as práticas que são usadas em quatro workflows de Git nesse quesito.
Branching é uma técnica poderosa. Poderosa, mas fácil de usar em excesso, muitas vezes se torna uma armadilha para os incautos e inexperientes. Os sistemas de controle de versão podem ajudar a controlar branches, rastreando cuidadosamente as mudanças, mas no final só podem agir como testemunhas dos problemas.
Existem problemas cotidianos, como vários desenvolvedores contribuindo para uma única base de código, onde o uso criterioso de branching é essencial. Mas devemos sempre ter cuidado com isso e lembrar a observação de Paracelso que “a diferença entre o remédio e o veneno está na dose”.
Então a primeira recomendação é: sempre antes de abrir um branch defina precisamente seu escopo, certifique-se que é o menor possível e não realize tarefas fora deste escopo nele. Quanto maior for o escopo da branch, maior será o risco de ter um merge problemático.
Daí a próxima diretriz: diminua o número de branches ativos, se possível a menos de três. Existe uma maneira de resolver seu problema diminuindo a complexidade ou a melhorando a modularidade? Pode melhorar seu pipeline de implantação? Uma tag é suficiente? Que mudanças em seu processo tornariam esse branch desnecessário? É bem provável que o branch seja, de fato, a melhor rota a seguir agora, mas é um fedor que está o alertando para um problema mais profundo que deve ser resolvido nos próximos meses. Livrar-se da necessidade de um branch é geralmente uma coisa boa.
Tente dobrar sua frequência de integração. Há obviamente um limite aqui, mas não estará perto dele a menos que esteja na zona de Integração Contínua. Haverá barreiras para a integração com mais frequência, mas são muitas vezes exatamente as que precisam ser eliminadas, de modo a melhorar o seu processo de desenvolvimento.
Como o merge é a parte mais difícil do branching, preste atenção no que está dificultando o merge. Às vezes é um problema de processo, às vezes é uma falha do design de alto nível. Qualquer problema de merge, especialmente um que causa uma crise, é um sinal para melhorar a eficácia de um time. Lembre-se que os erros só são valiosos quando se aprende com eles.